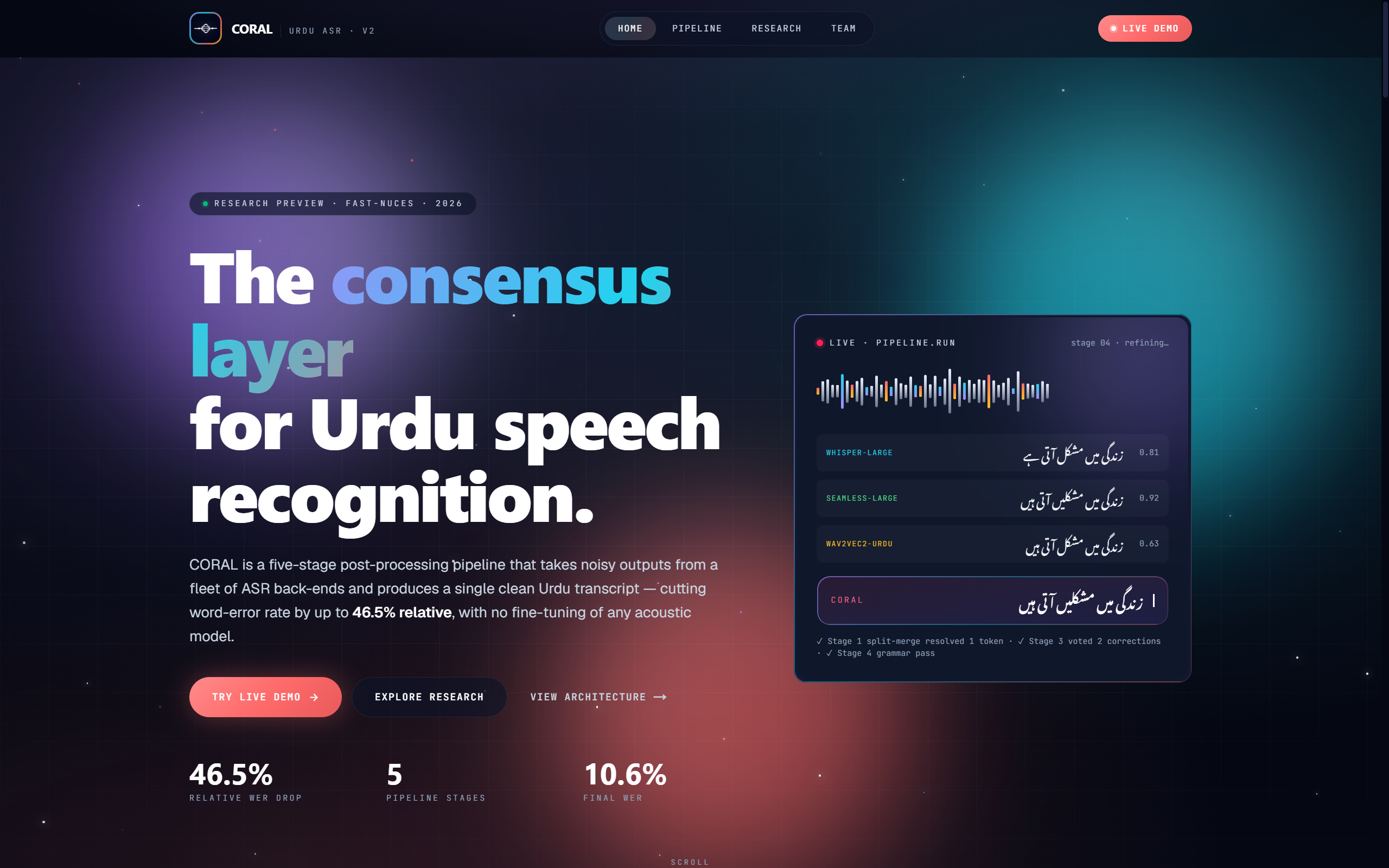
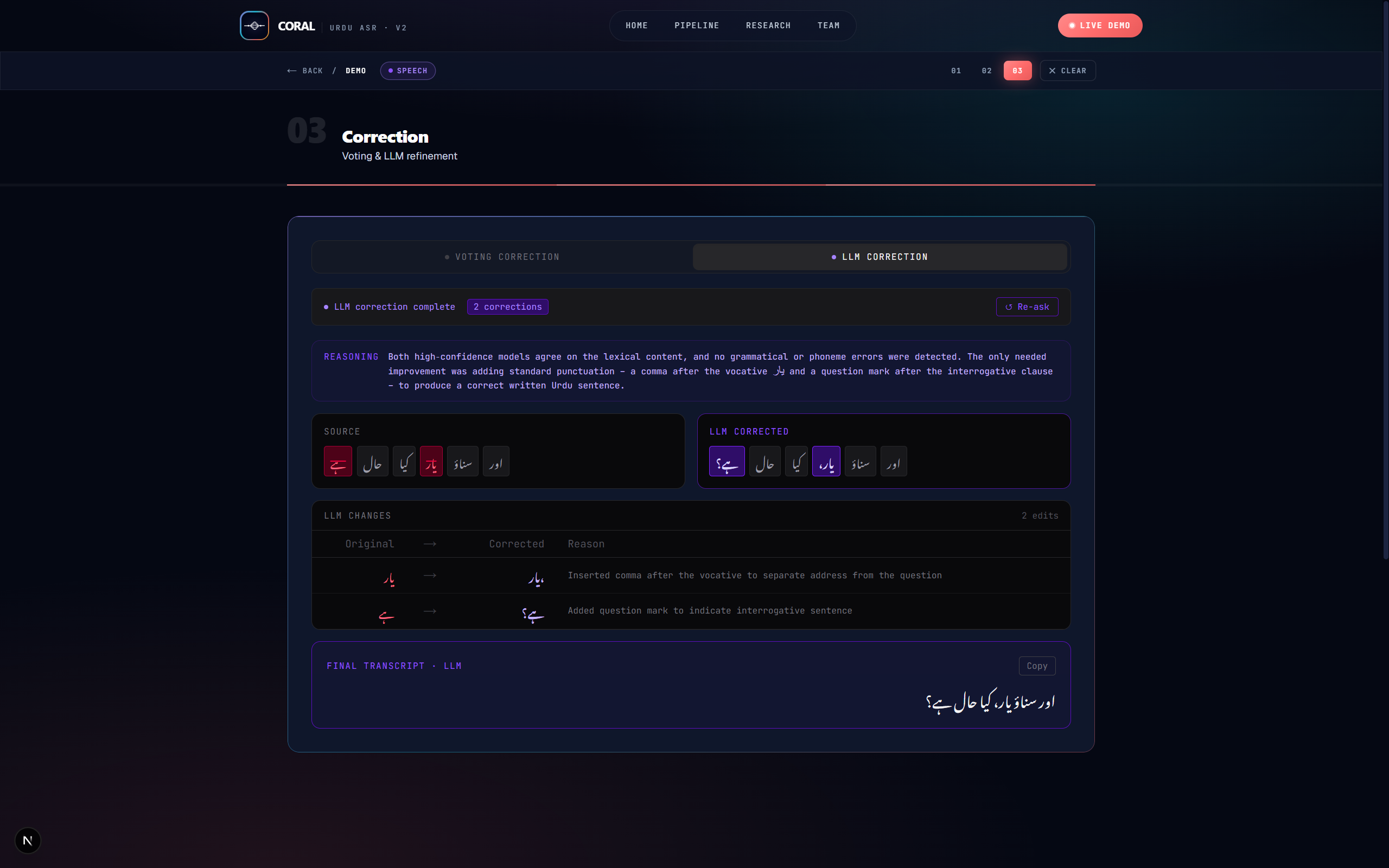
Final Year Project: a five-stage Urdu ASR post-processing platform that converts noisy ensemble speech-recognition outputs into a single cleaner Urdu transcript, reducing Word Error Rate by up to 46.5% relative without retraining acoustic models.
Final Year ProjectUrdu ASRPythonFastAPINext.jsReactTypeScriptTailwind CSSHuggingFaceKaggle GPUngrokDuckDBBK-treeN-gram LMLLM Refinement
Urdu ASR systems often disagree on word boundaries, split/merge decisions, and OOV tokens. CORAL treats that disagreement as a signal, aligns model outputs, corrects lexical errors, and produces a cleaner transcript without retraining the acoustic models.
Architecture overview
Next.js research/demo frontend -> FastAPI pipeline orchestrator -> HuggingFace data assets and DuckDB n-grams -> Kaggle GPU ASR nodes registered through ngrok -> optional bounded LLM refinement.
Challenges & learnings
Designed split-merge-aware alignment so word-boundary disagreement between ASR models could be classified and used during correction.
Built OOV retrieval with a 500K-word Urdu corpus, BK-tree fuzzy lookup, and n-gram re-ranking.
Integrated distributed live ASR inference where Kaggle GPU notebooks self-register with the FastAPI backend.
Balanced deterministic research-grade correction with an optional bounded LLM polish for Urdu grammar, izafat, postpositions, and code-switching.
Features
-Five-stage ASR correction pipeline: Urdu normalization, split-merge alignment, OOV/BK-tree lookup, consensus voting, and bounded LLM refinement
-Research website with cinematic landing page, pipeline walkthrough, results dashboard, team page, and in-browser demo
-FastAPI orchestrator with registry endpoints for live Kaggle GPU ASR model nodes
-HuggingFace-backed data tier for BK-tree and n-gram assets with DuckDB startup loading
-Evaluation on Common Voice Urdu and conversational Urdu with additive WER reductions across stages
Visuals & outputs
Screenshots, visual outputs, and project artifacts.